
When it comes to website accessibility on SERP you must know what is crawling & indexing in SEO? What are the benefits? How it works? And if you are not aware of these things, you must read this article it will let you understand how crawling & indexing is a key feature that needs to be considered. Moreover, how it can be used for your website to rank higher.
Although, SEO is considered as deep sea but I’ll let you know something that has a vital role in web world. I’ll first like you to start with the definition so that you get the basic concepts clear.
What is crawling?
It is the process in which a website URL’s are crawled by Googlebot or Google’s Spider (Web crawler) for tracking purpose. This is the reason why Sitemaps are created; it is a xml file where website owners can list web pages of their site to tell Google and other search engines about pages on the website.
Sitemaps helps in finding all pages that are on site which may not be found in normal crawling process. You can easily generate Sitemap for your site using “XML Sitemap Generator” tool.
The pages that are not crawled are not indexed by search engines and therefore it is crucial to make sure that the pages on website are crawled as it should be. This helps with search engine optimization as it makes easier for Google & other search engines to discover the content on your site so that they can serve it up in the SERP.
What is indexing?
Once crawling has been done, the web pages get placed onto Google’s index. All you need to do is check if your web pages are actually being indexed and actively monitor for issues. You can compare the cached version and actual version to know if your web pages are indexed properly.
Whenever any search query is performed by a web user, Google goes through the index list and find relevant web page to show them on search results.
How it works?
Googlebot goes through all the links, on the basis of numerous factors it decides if the web page is good enough to be crawled and bring it to Google server. Once the web page is crawled it becomes the part of world wide web. All of these data is stored on the server and whenever any search query is made by the user, Google ensures if they are served relevant information.
Google ranks the site after matching the keywords, location, videos, images, publishing dates, content and so on. If you want to get new information or want your updated webpage and/or site to be shown on search engines, it needs be completely recrawled.

Major factors that affect crawling and indexing
Are your web pages not getting indexed? There can be certain reasons behind it. Here are some major factors that affects crawling and indexing.
1. Domain name: Domain name with the main keywords are given more preference. Also, there many ways to create a user friendly domain. Know these techniques by reading this article “Best Practices for Domains.”
2. Backlinks: The more number of quality backlinks, higher will be your chances of acknowledgement by search engine. External linking makes your website trustworthy and reputable.
3. Internal linking: Internal linking is the easiest and important factor to attain ranking goals. It connects your content which is important from user perspective. Through internal linking Google gets an idea of site architecture and passes the link juice.
4. XML sitemap: Submit XML sitemap as soon as you have created a website. It will automatically inform Google to check your site updates.
5. Duplicate content: You must have heard the phrase “Content is King”, we can’t say that it is completely true but yes it is crucial. Duplicate content can be tremendously bad for your website.
6. Meta tags: It influence user and increases your click-through-rate. Including main keywords and having unique meta tags are considered as in SEO best practices. To know more you may refer this awesome article “Learn How to Create Meta Tags for Your Website.”
7. URL canonicalization: Canonicalization is the process of choosing the best URL when there are several choices for the same page, you must clearly tell Google which URL is authoritative (canonical) for that page. It is crucial to have an SEO friendly URLs for each page. It is actually vast, you can refer this amazing article by Matt Cutts “SEO advice: url canonicalization.”
Google Webmaster Tools is a free tool that can be used for crawling, monitoring indexation, index status, crawl status and much more. This tool lets you find whether the page is indexed and how many of them are indexed. Refer this article that will help you further understand “How to Use Google Webmaster Tools for SEO.”
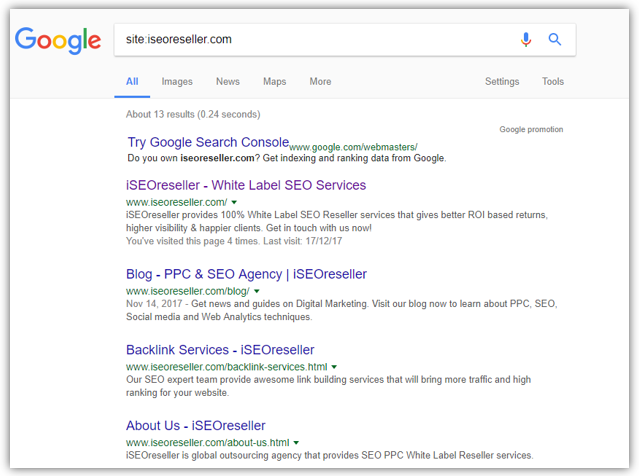
You can also simply check it on Google if your web page is being indexed or not. Just type site:iseoreseller.com in Google search bar. If your site is previously crawled, it will display you list related to the search which you can see in below screenshot:
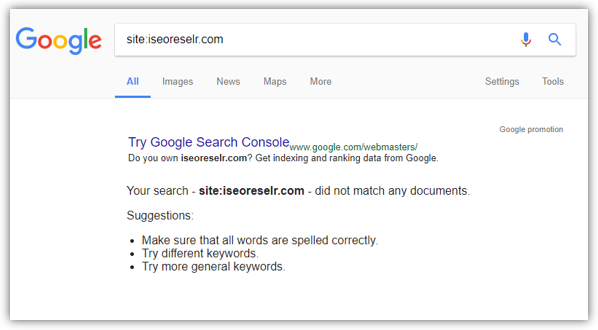
And if your site is not already crawled by Google, you’ll see no results found as below:
Tips & tricks
• Keep your Sitemap updated and accurate
• Always index only those pages that are important to your website
• Never index unnecessary archives like tag, categories and all other useless pages
• You can use robots.txt file to stop crawling certain parts of the website. Here is an ultimate article that will help you understand “how to create robots.txt file”
In closing
Hope this article has shown you light in deep sea of SEO and helped you see the benefits of crawling and indexing. I have much more to share on SEO techniques that will help you widen your understanding of seo. I’ll keep you in loop and will soon update you with a next big thing.
Reference - 11 Solid tips to increase Google crawl rate of your website - How to get Google to index your new website & blog quickly
